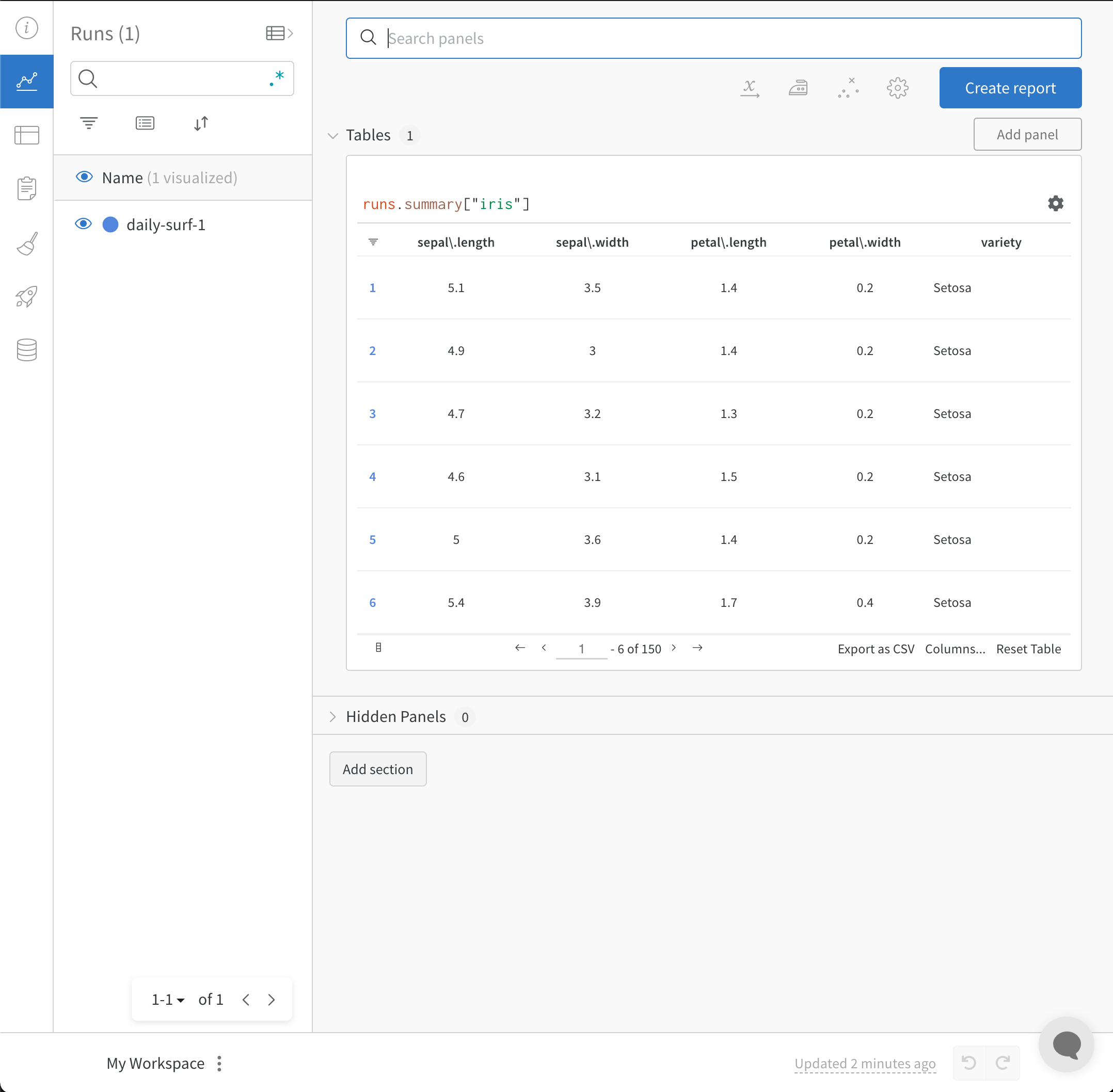
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
run = wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
)
for key, val in metrics.items():
if isinstance(val, list):
for _val in val:
run.log({key: _val})
else:
run.log({key: val})
run.summary.update(summaries)
run.finish()